Interviewer: Why Is the Query with “LIMIT 0, 10” Fast While the Query with “LIMIT 1000000, 10” Slow in MySQL?
Firstly, let’s assume that we have already created .....

My articles are open to everyone; non-member readers can read the full article by clicking this link.
Recently, a friend of mine encountered such a question during an interview. In MySQL, assuming there are tens of millions of records in a table, why is the query with “LIMIT 0, 10” very fast, while the query with “LIMIT 1000000, 10” is very slow?
Let’s analyze it together.
Firstly, let’s assume that we have already created a table named Student and inserted 5 million student records into it. The following are the example SQL statements for creating the table and inserting some of the data:
-- Create a table named 'Student' to store student information.
CREATE TABLE Student (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
age INT,
gender ENUM('Male', 'Female'),
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Here is the stored procedure for inserting 5 million student records:
DELIMITER //
CREATE PROCEDURE insert_students()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 5000000 DO
INSERT INTO Student (name, age, gender) VALUES (CONCAT('Student', i), FLOOR(RAND() * 100), ELT(FLOOR(RAND() * 2 + 1), 'Male', 'Female'));
SET i = i + 1;
END WHILE;
END //
DELIMITER ;
-- Call a stored procedure to insert data.
CALL insert_students();
Please note that inserting 5 million records may take a relatively long time, and the specific duration depends on the performance of your database.
Next, we will use “LIMIT 0, 10” and “LIMIT 1000000, 10” respectively to query the data.
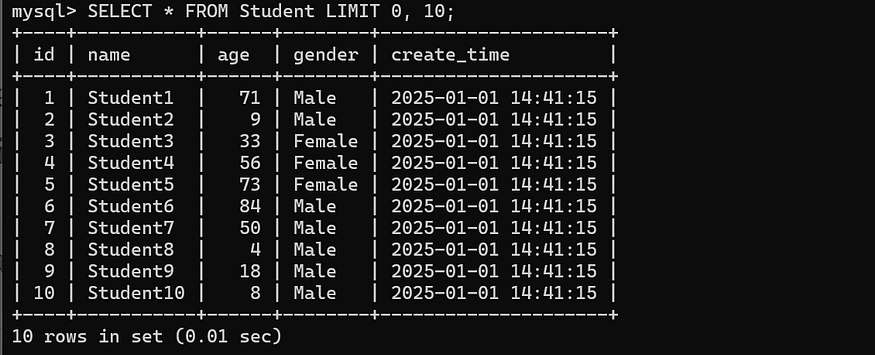
-- Query the first 10 students.
SELECT * FROM Student LIMIT 0, 10;
-- Query 10 students starting from the 10,000,001st student.
SELECT * FROM Student LIMIT 10000000, 10;
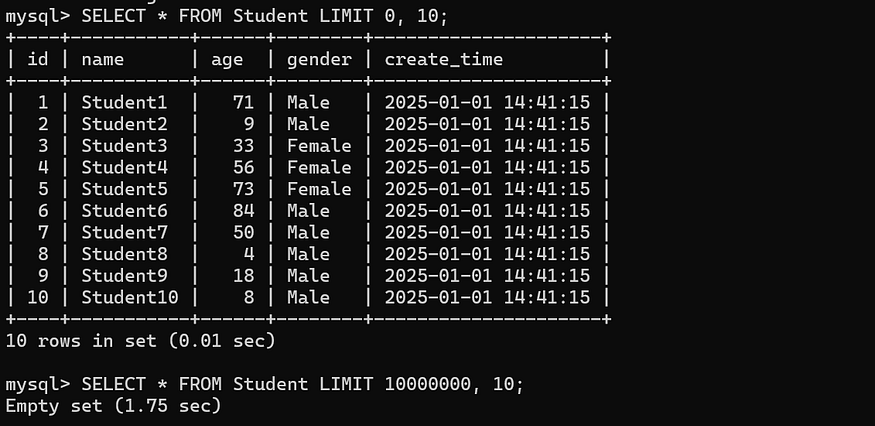
It can be seen that the difference in the time-consuming between the two is very large, and the query has changed from a millisecond-level query to a second-level one!!!
So, it can be seen that the larger the value of X in LIMIT, the slower the query speed.
This problem is actually a typical deep pagination problem in MySQL. Then the question comes: why does the query become slower as the LIMIT offset gets larger? And how to optimize the query speed?
Why does the query speed get slower as the value of X in LIMIT becomes larger?
In fact, this is mainly because the database needs to scan and skip X records before it can return Y results. As X increases, the number of records that need to be scanned and skipped also increases, resulting in a decline in performance.
For example, LIMIT 1000000, 10 requires scanning 1000010 rows of data and then discarding the first 1000000 rows, so the query speed will be very slow.
Optimization Methods
There are two typical optimization methods for the deep pagination problem in MySQL:
Starting ID Positioning Method: Use the last ID of the previous query as the starting ID for the query.
Covering Index + Subquery.
Method 1. Starting ID Positioning Method
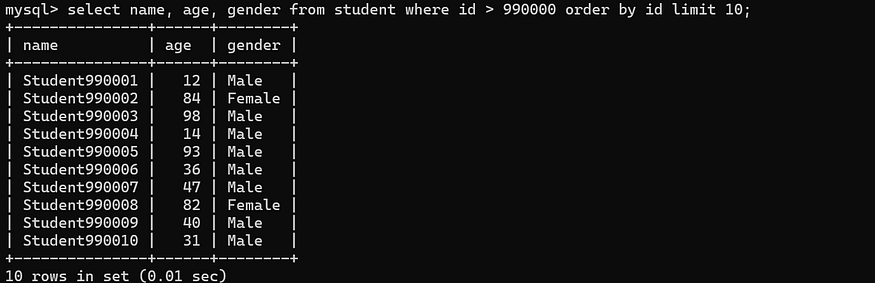
The Starting ID Positioning Method means specifying a starting ID when using the LIMIT query. And this starting ID is the last ID of the previous query. For example, if the ID of the last record in the previous query is 990000, then we start scanning the table from 990001 and directly skip the first 990000 records, so the query efficiency will be improved. The specific implementation SQL is as follows:
select name, age, grade from student where id > 990000 order by id limit 10;
It can be seen that the query only takes 0.01 seconds.
Why is the query with the starting ID highly efficient?
The reason why the query with the starting ID is highly efficient lies in that it makes full use of the B+ tree structure of the primary key index in the database. The last ID determined at the end of the previous query is just like an accurate positioning marker, enabling the current query to start directly from this marked position.
The leaf nodes of the B+ tree are connected by a doubly linked list. When there is a definite starting ID, the database doesn’t need to blindly scan and skip a large number of records as in the ordinary LIMIT query. Instead, it can traverse backward along this doubly linked list in a targeted manner and quickly find the subsequent records that meet the conditions.
This approach avoids processing a large amount of irrelevant data, greatly reduces the operational overhead of the database, and thus significantly improves the speed and efficiency of the query.
As shown in the following figure:
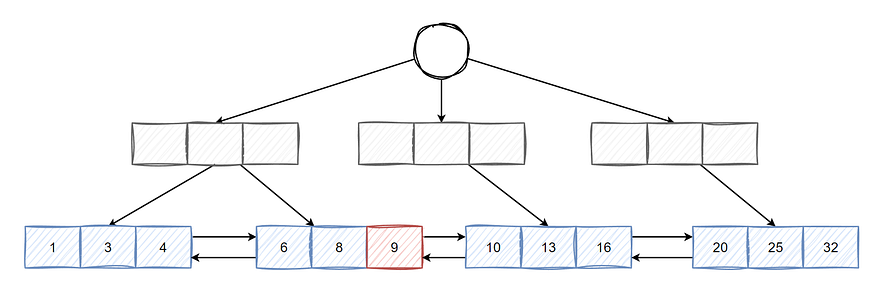
If the result of the previous query is 9, then when querying again later, it only needs to traverse N pieces of data after 9 to get the result, so the efficiency is quite high.
Analysis of Advantages and Disadvantages
This query method is more suitable for querying data page by page, such as the waterfall flow mode when browsing news in a mobile app.
However, if the user jumps between pages, for example, directly querying the 100th page after querying the 1st page, then this implementation method is not very appropriate.
Method 2. Covering Index + Subquery
If you are observant, you may notice that our previous query statements didn’t have any conditions, which actually doesn’t quite conform to the actual application scenarios.
Suppose we now have a list requirement to be able to query student information in reverse order of creation time and paginate it. The SQL before optimization is as follows:
select name, age, gender, create_time from student order by create_time desc limit 1000000,10;
Execute it and see how much time it takes to query the 10 next pieces of data after the 1 millionth record under the condition of having 5 million pieces of data.
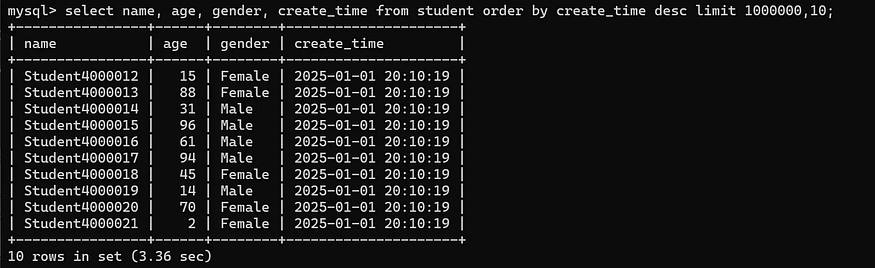
It can be seen that it actually takes 3 seconds!!! Certainly, obvious lags will be noticed at the user level, and the user experience is very poor.
Let’s then take a look at how much time it will take if we change it to limit 0, 10.
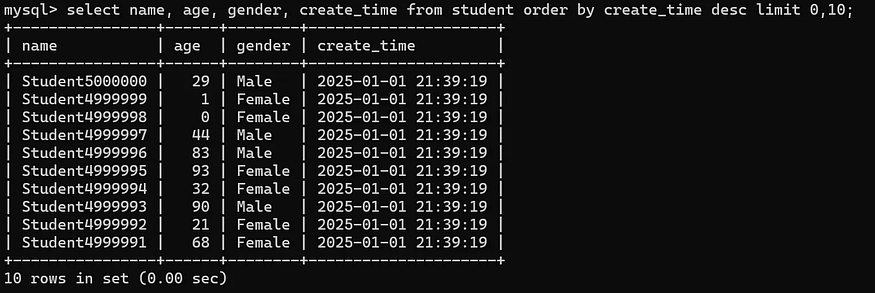
Almost can’t feel it at all. 😊
Then why does deep pagination become slower?
I believe you will surely say that it’s because it will scan 1000010 rows of data that meet the conditions, and then discard the first 1000000 rows before returning.
However, that’s not the only reason.
In the above SQL, an index has been created for the create_time field, but the query efficiency is still very slow. That's because it has to fetch 1000000 complete pieces of data, including fields without indexes such as name, age, and gender. So it needs to perform frequent lookups back to the table, resulting in very low execution efficiency.
At this time, we can make the following optimizations:
select t1.name, t1.age, t1.gender, t1.create_time from student as t1
inner join
(select id from student order by create_time desc limit 1000000,10) as t2 on t1.id = t2.id;
Let’s then take a look at the execution time consumed.

It only takes 0.23 seconds.
Compared with the original SQL, the optimized SQL effectively avoids frequent lookups back to the table. The key lies in that the subquery only retrieves the primary key IDs. By taking advantage of the index coverage technique, it first accurately locates a small number of primary key IDs that meet the conditions, and then queries based on these primary key IDs later, which significantly improves the query efficiency and reduces the query cost.
Index coverage is a database query optimization technique. It means that when executing a query, the database engine can directly obtain all the required data from the index without having to go back to the table (access the primary key index or the actual data rows in the table) to obtain additional information. This way can reduce disk I/O operations and thus improve query performance.